Dialogue system review
The dialogue system can usually be divided into three categories based on the user's requirement: the "chit-chat" bot; the task-oriented bot; and the knowledge-inquiring (question-answering) bot. These three types are not mutually exclusive, and there are combined scenarios, like a virtual docent can be both a chit-chat and a knowledge-inquiring bot. Apart from the above, we can also classify the dialogue system into a single-turn and multi-turn conversational bot, depending on whether to consider the conversation context information. This article starts with the "chit-chat" bot.
The "chit-chat" bot: can use 1. generative-baed approach, 2. retrieval-based approach, or 3. combined approach.
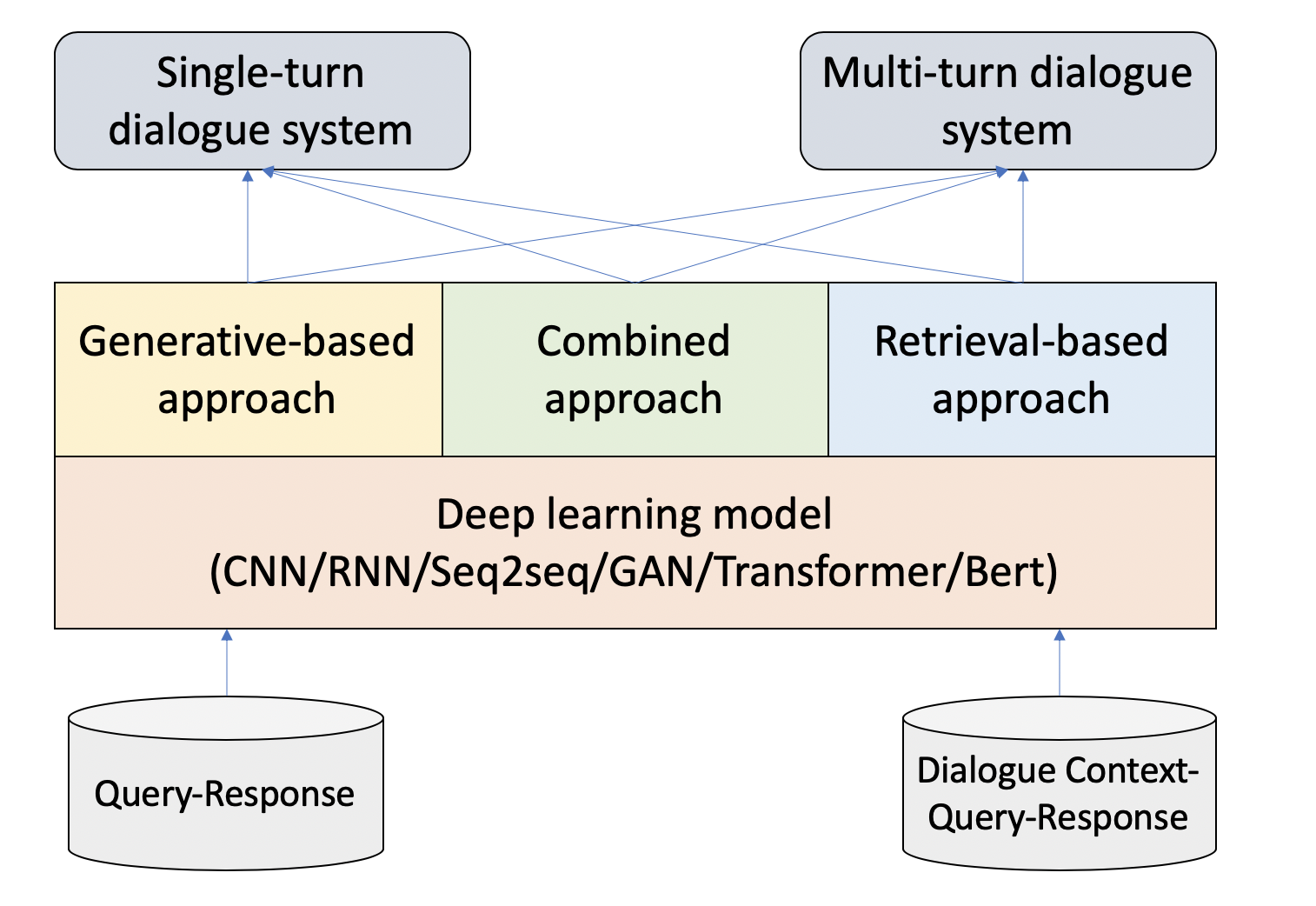 Fig.1 - Dialogue system.
Fig.1 - Dialogue system.
1. Generative-based approach
The approach can be regarded as a seq2seq model, which obtains great success in the machine translation problem. However, machine translation is more like an objective problem with objective criteria/metrics; while, the dialogue generation is more like a subjective problem with no standard answer [2]. Therefore the assessment for dialogue generation is a troublesome problem, there are a few research works on the dialogue assessment like ADEM and RUBER. Generally, the dialogue generation is a conditional generation problem that requires high coupling between query and answers.
Due to its low reply quality and uncontrollable, the industry prefers to retrieval-based approach that is more practical and robust.
2. Retrieval-based approach
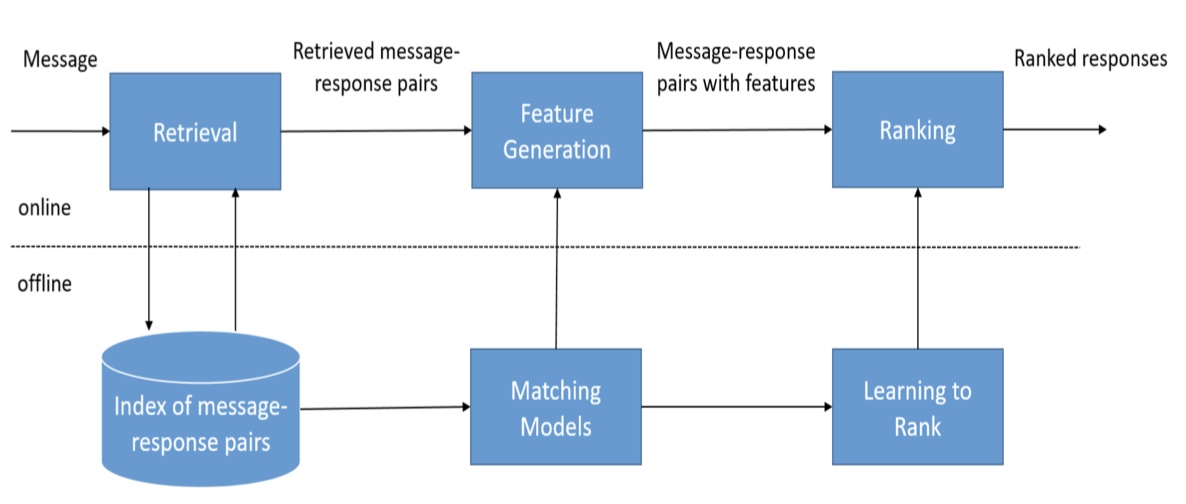 Fig.2 - Retrieval-based conversation approach.
Fig.2 - Retrieval-based conversation approach.
The retrieval-based approach studies the response selection. It is suitable for both chitchat and knowledge-inquiring/QA tasks. For QA/FAQ knowledge-inquiring task, single-turn conversation dominates most cases. However, the chit-chat is more incline to multi-turn and context-based. For the dataset, the FAQ is usually closed-domain, and it is easy to get, for example, the corporate documents; while the chit-chat usually has no scope limit and is open-domain, thus the query-response pairs corpus is needed, that is we need to crawl the dialogue corpus from public social media like Twitter, Facebook, and Instagram.
The core of the retrieval-based approach is to construct the (query-response/context-query-response) matching. Some people may found confused when reading research papers about relevance matching and semantic marching [1]. The relevance matching is to rank documents by relevance to a user's query. The semantic matching is used to measure the semantic distance between two pieces of short texts. In other words, the relevance matching is fundamentally an information retrieval (IR) matching task, it operates directly on the similarity matrix obtained from products of query and document embeddings and builds modules on top to capture additional n-gram matching and term importance signals. On the other hand, semantic matching is more an NLP task, which requires more semantic understanding, contextual reasoning, and co-attention (context-aware) rather than specific term matches. In the dialogue system, semantic matching is a better choice.
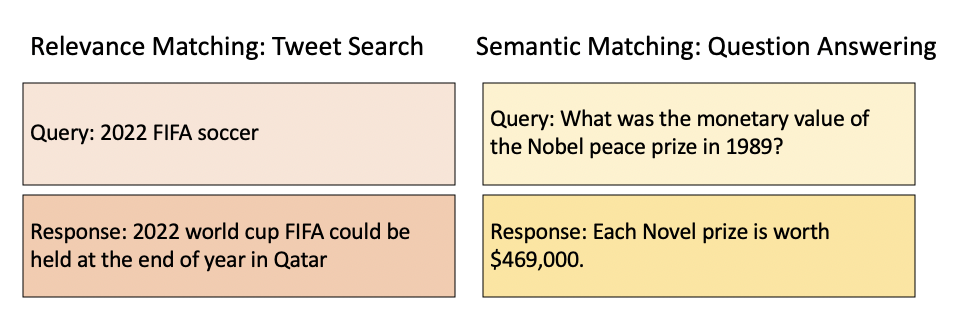 Fig.3 - Relevance matching vs semantic matching.
Fig.3 - Relevance matching vs semantic matching.
2.1 single-turn conversation
For single-turn conversation, we ignore the conversation history and only focus on the query-response matching, the mainstream methods include semantic representation-oriented technique and semantic interaction-oriented technique.
2.1.1 representation-oriented technique
In the representation oriented framework, the deep learning technique is employed to focus on the mapping of objects from the original text space to the feature space, that is, to calculate the embeddings of query and documents that contain candidate responses.
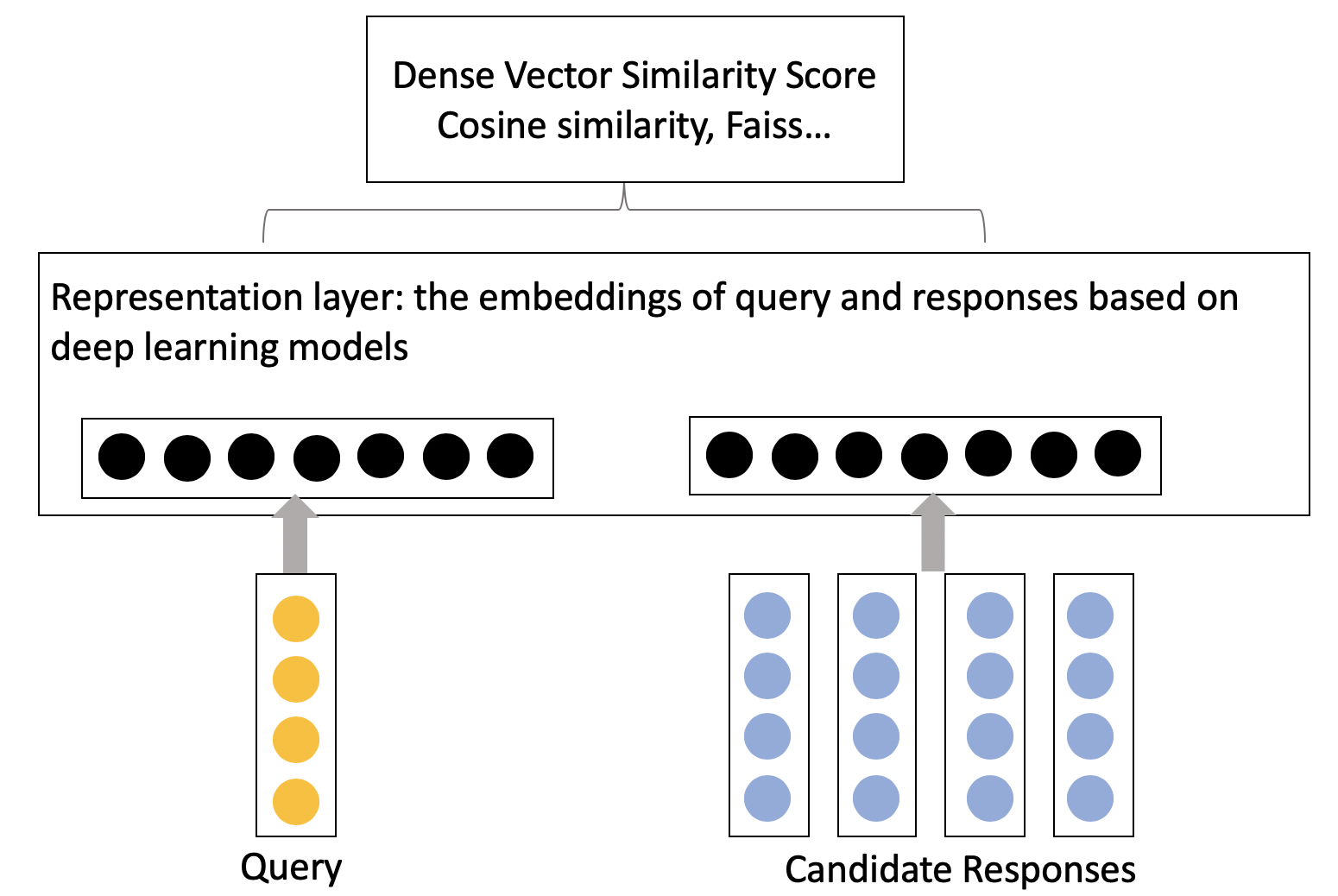 Fig.4 - Representation-oriented cconversation model.
Fig.4 - Representation-oriented cconversation model.
Currently, many contextual pre-trained sentence embedding models, such as Elmo, BERT (and its variants), GPT family, can be applied and fine-tuned to get a satisfying result.
2.1.2 interaction-oriented technique
The interaction-oriented technique model the semantic interaction structure between reply and query, focusing on capturing the meaningful interaction matching information from words, phrases, and sentences of reply and query. Fig.5 illustrates an example of interaction structure at different levels.
 Fig.5 - interaction-oriented cconversation model..
Fig.5 - interaction-oriented cconversation model..
One of the classic interaction-oriented technique for conversation, I would like to introduce here, is the MatchPyramid model [4]. The overview of the MatchPyramid model is shown in the Figure below. Firstly, a matching matrix whose entries represent the similarities between words is constructed and viewed as an image. Then a convolutional neural network is utilized to capture rich matching patterns in a layer-by-layer way. By resembling the compositional hierarchies of patterns in image recognition, the MatchPyramid model can successfully identify salient signals such as n-gram and n-term matchings.
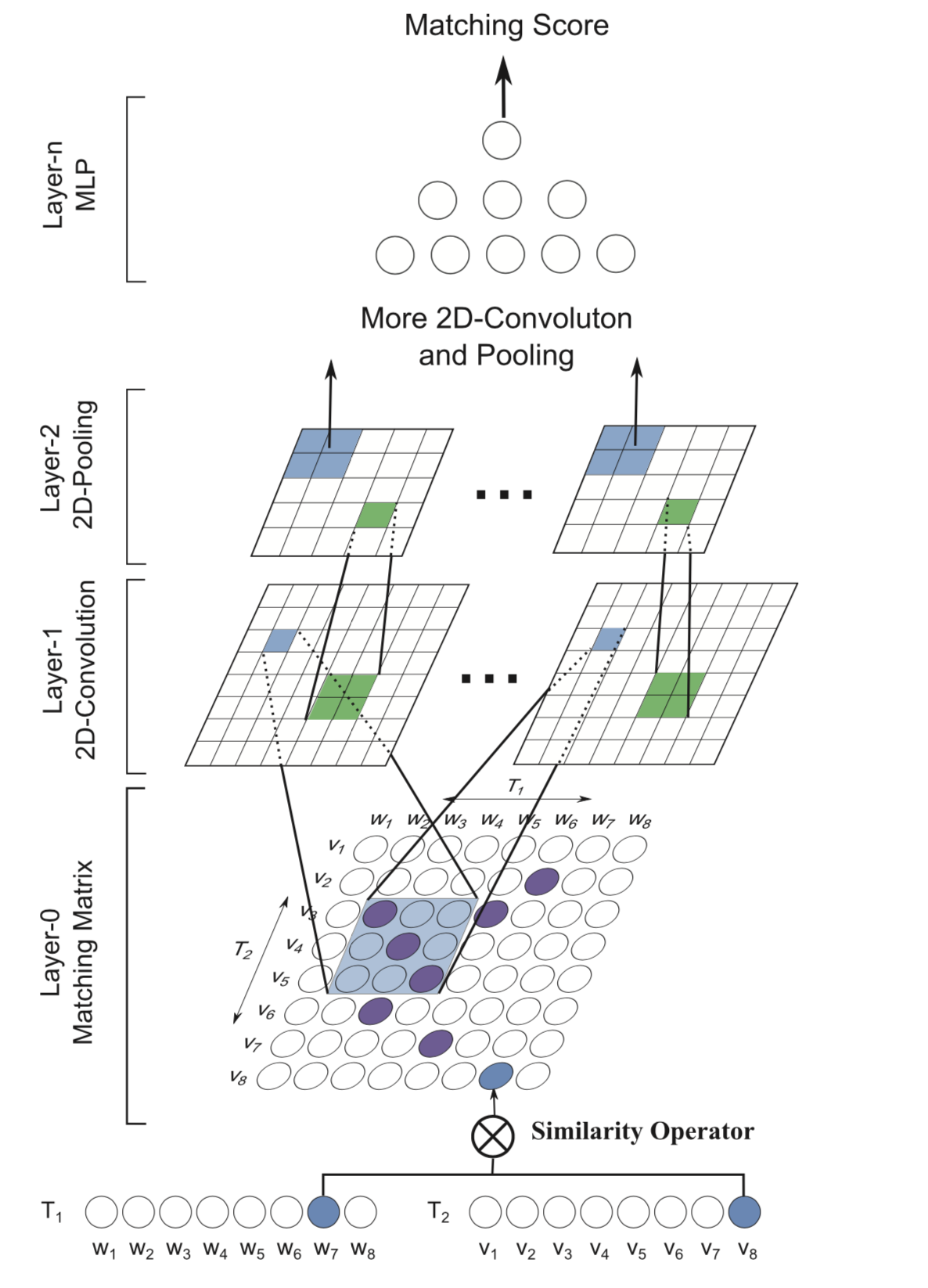 Fig.6 - Match Pyramid interaction matching model.
Fig.6 - Match Pyramid interaction matching model.
2.2 multi-turn conversation
The biggest difference between a single-turn and a multi-turn conversation model is that the multi-turn conversation model needs to integrate the current query and history conversation as input; its goal is to select a candidate response, which is relevant to the current query as well as corresponding to the conversation context, Fig.7. Still, the mainstream technique can be divided into representation-oriented and interaction-oriented.
 Fig.7 - An example of multi-turn conversation.
Fig.7 - An example of multi-turn conversation.
2.2.1 representation-oriented technique
Each conversation text is called an utterance. The diagram of the representation-oriented technique for multi-turn conversation is shown in Fig.8. For the utterance representation layer, pre-trained language models like Elmo, BERT, GPT can be applied to calculate the embeddings. For the context representation layer, a simple way is using the pooling technique; autoencoder, DNN, and RNN can also be used to learn the context representation layer from sentence embeddings if you have enough duplicate conversation corpus. Apart from matching a response with a highly abstract context vector, other existing work may concatenate utterances in context, however, these representation-oriented approaches prone to lose relationships among utterances or important contextual information, thus we can turn to the interaction-oriented technique.
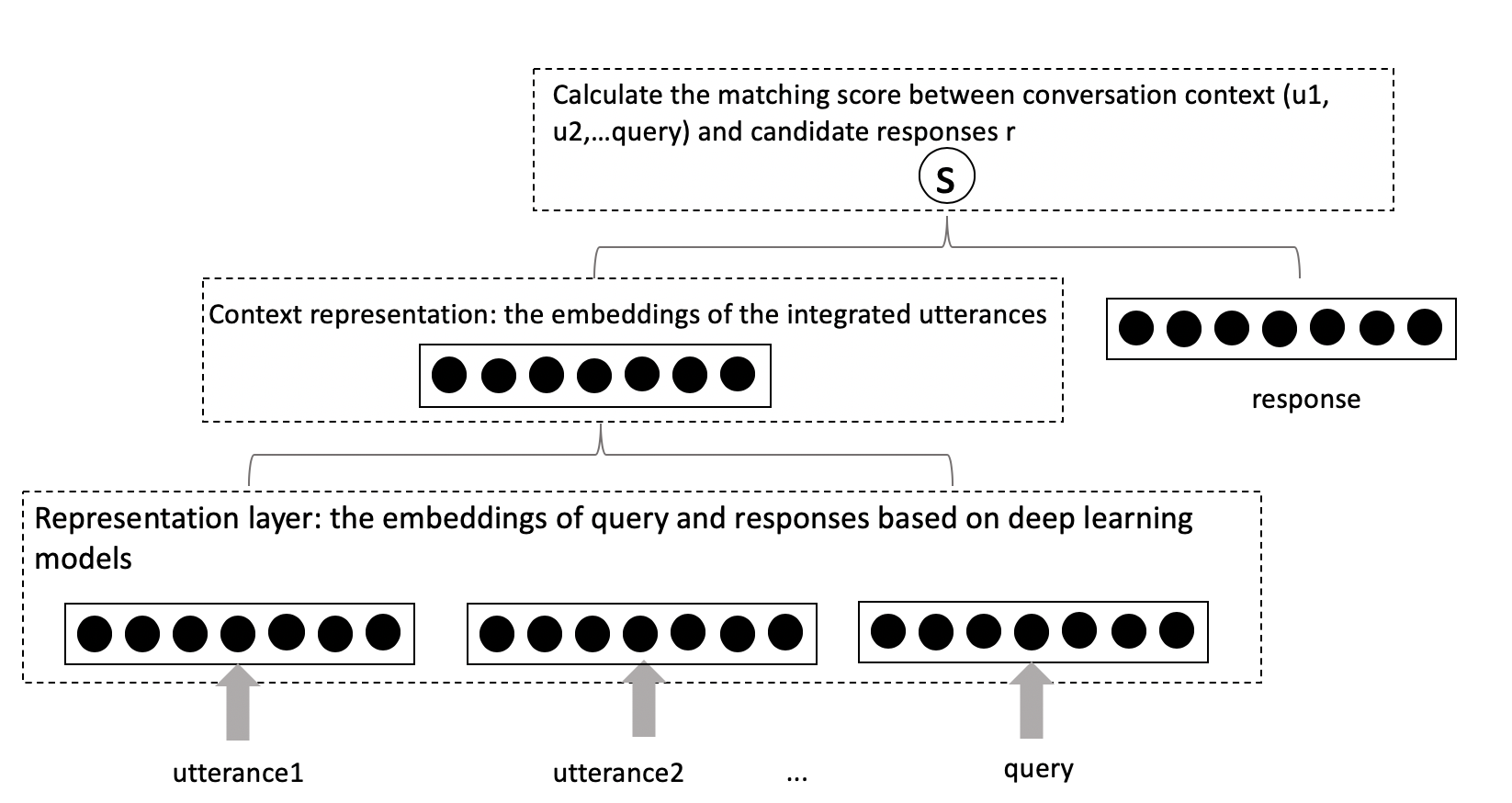 Fig.8 - Diagram for retieval-based representation-oriented multi-turn conversation model.
Fig.8 - Diagram for retieval-based representation-oriented multi-turn conversation model.
2.2.2 interaction-oriented technique
Compared to the representation-oriented technique, the interaction-oriented technique models the interaction pattern between the candidate response and each utterance, hence this approach calculates the matching score in a finer semantic granularity, refer to Fig.9.
 Fig.9 - Diagram for retieval-based interaction-oriented multi-turn conversation model.
Fig.9 - Diagram for retieval-based interaction-oriented multi-turn conversation model.
Paper [5] proposed a sequential matching network (SMN), which is motivated by the Match Pyramid model. SMN first matches a response with each utterance in the context on multiple levels of granularity and distills important matching information from each pair as a vector with convolution and pooling operations. The vectors are then accumulated in chronological order through an RNN which models relationships among utterances. The final matching score is calculated with the hidden states of the RNN.
2.2.3 Dataset for multi-turn conversation
-Ubuntu Dialogue Corpus (English)
-Douban Conversation Corpus (Chinese)
Till now (2020 June), the representation-oriented technique using pre-trained language model BERT achieves the best performance on Ubuntu Dialogue Corpus [6].
2.2.4 Metrics
R2@1, R10@1, R10@2, R10@5.
The knowledge-inquiring/question-answering bot:
1. FAQ single conversation model
2. CoQA benchmark
3. KB-dialogue study
[1]. Bridging the Gap Between Relevance Matching and Semantic Matching for Short Text Similarity Modeling.
[2]. https://zhuanlan.zhihu.com/p/83825070
[3]. Survey on deep learning based open domain dialogue system, chinese journal of computers.
[4]. Text Matching as Image Recognition, AAAI 2016.
[5]. Sequential Matching Network, arxiv 2017.
[6]. Domain Adaptive Training BERT for Response Selection.
_20160215122753_1080p.jpg)
